Try our cookiesAlza.cz a. s., Company identification number 27082440, use cookies and other data to ensure the proper functioning of the website and, with your consent, also, among other things, to personalize advertising and the content of our websites. By clicking on the “I understand“ button, you agree to the use of cookies and the transfer of data regarding the behavior on the website for displaying targeted advertising on social networks and advertising networks on other websites.
We use 8 categories of cookies on our website:
Technical cookies
These are strictly necessary for the functioning of the website and the features you choose to use. Without them, our website would not work; you wouldn't be able to log in to your user account, for example.
Functionality cookies
These cookies allow us to remember your basic choices and improve the user experience. These include remembering your preferred language or allowing you to stay logged in permanently.
Social media cookies
These cookies allow us to easily link you to your social media profile and, for example, allow you to share products and services with your friends and family.
Content personalisation
These cookies allow us to show you content and ads according to the information we have about you to best meet your needs. This includes what content you have viewed, or on what device you are accessing our website.
Non-personalised advertising
These cookies allow us to show you general ads for products and services.
Personalised advertising
Thanks to these cookies, we and our partners can offer you relevant products and services based on your purchases, your shopping behaviour and your preferences.
Audience metrics
These cookies allow us to optimise our site for your convenience based on how you use it. The aim is to remember or anticipate your choices. This includes, for example, the use of features, their location, or the behaviour on the page.
By giving your consent to the processing of cookies, functionality and analytical cookies will be installed on the device you use to browse the website (click on the "I understand" button for both categories, or you can select only one of the categories by clicking on the "Settings" button). We always install technical cookies on your device, even without your explicit consent, because without them our website would simply not work.
You can revoke your consent to the processing of cookies. In connection with our company's cookie processing, you also have the following rights: the right to access cookies, delete, modify, supplement and correct them, restrict processing and the right to lodge a complaint with the Office for Personal Data Protection. Read more about your rights.
V závěrečné části našeho seriálu se podíváme na to, jak s umělou inteligencí souvisí Bitcoin, co na to regulátoři, zda nás zničí SkyNet jako ve filmu Terminátor a zda všichni přijdeme o práci.
V úvodní části seriálu jsem propojil internet, umělou inteligenci a Bitcoin. Internet propojil mysli, umělá inteligence nám pomůže zlepšit naše schopnosti (zvýší nám inteligenci) a Bitcoin umožní přenos hodnoty v čase i prostoru. Ve všech třech případech je podstatné, aby to bylo bez zásahu třetích stran – bez cenzury, bez manipulace a podobně.
Nehledě na filozofické řeči - má smysl uvažovat o umělé inteligenci v kontextu Bitcoinu? Možná mnohé čtenáře nyní polil studený pot a myslí si, že se v následujícím odstavci dočte nějaké halucinace o propojení umělé inteligence a blockchainu, jak měly ve zvyku v roce 2017 různé ICO projekty. Zklamu vás, budeme se bavit pouze o Bitcoinu a nebudeme dávat umělou inteligenci na blockchain.
Peníze a tedy i Bitcoin umožňují koordinaci přerozdělování vzácných zdrojů. Pro umělou inteligenci jsou vzácnými zdroji výpočetní výkon – na trénování a na inferenci, a za jistých okolností data, i když díky „dědičnému hříchu“ internetu jsme si zvykli, že je na něm všechno „zdarma“, a tedy platíme svými daty a pozorností, tedy data často nejsou velmi vzácná.
Crowdfunding, soutěže a český Common Voice
Neplatí to ovšem vždy. Některá data je třeba „odmakat“, jak tomu bylo například v případě projektu ImageNet. Jedním ze známých problémů ekonomie je financování tzv. „veřejných statků“, kdy není možné (nebo chtěné) ze spotřeby vyloučit tzv. černé pasažéry. Pokud někdo postaví malý můstek přes řeku, teorie říká, že není možné vyloučit kohokoli, aby jej využil. Ve skutečnosti to možné je (turniket, mýtné, předplatné). Problém veřejných statků popisuje velmi dobře Robert Chovanculiak v knize Pokrok bez povolení, kde jedním z řešení tohoto problému je crowdfunding. Pokud se použije na financování tvorby veřejných statků, s černými pasažéry počítá, ale přispěvatelům na veřejné statky slibuje jiné odměny. Například zmíněný problém mostu vyřešili v Rotterdamu crowdfundingovou kampaní, kde černé pasažéry nevyloučili z používání mostu. Most Luchtsingel mohou využívat všichni chodci, ale ti, kteří přispěli na jeho stavbu, mají do dřeva vyryto své jméno – získali něco navíc oproti „černým pasažérům“.
Most Luftsingel v Rotterdame. Fotografia: Mike van den Bos, Unsplash
Dalším principem financování veřejných statků je soutěž s incentivami. Tak v hackerské komunitě často fungují hackathony – soutěže, které jsou zaměřeny na řešení užší či širší zadefinovaných problémů. Dnes nejznámější je Ansari X-Prize, která vyplatila odměnu prvnímu týmu, který vytvoří znovupoužitelné letadlo, které se dostane na oběžnou dráhu Země, přistane a do dvou týdnů to udělá znovu. Ve skutečnosti však tento princip je mnohem starší. Například ve 20. letech 20. století nabídl podnikatel Raymond Orteig odměnu 25000 dolarů prvnímu člověku, který uskuteční let bez mezipřistání mezi New Yorkem a Paříží. Po několika neúspěšných pokusech různých lidí se to podařilo v roce 1927 americkému letci Charlesi Lindberghovi se svým letadlem Spirit of St. Louis.
V umělé inteligenci jsou zapotřebí k trénování data. Jedním z projektů, který taková data sbírá, je projekt Common Voice nadace Mozilla Foundation. Projekt sbírá anotované záznamy hlasu v různých jazycích, pomocí kterých se trénují modely pro rozpoznávání hlasu. Záznamů hlasu v angličtině je poměrně dost, ale co třeba taková čeština? V prosinci 2022 například Marek Palatinus (slush) vyhlásil soutěž o 2x milion satoshi. Získali je muž a žena, kteří měli 26. 12. nejvíc nahrávek na Common voice v češtině. Benefitem pro všechny (včetně slushe) je to, že jim počítače budou lépe rozumět v češtině, když se nahrávky použijí při trénování nových modelů. Ti, co přispěli, měli kromě možnosti vyhrát cenu i benefit toho, že jejich hlasu bude počítač rozumět ještě lépe.
Vyhlašuji vánoční soutěž o 1.000.000 sats na LN!
Pravidla: 1. Založte na CV účet se stejným username jako na Twitteru. 2. Do komentáře pod tweet napište, že se účastníte. 3. Retweetněte tento tweet.
Účet s nejvíce nahrávkami k 26.12. v 12:00 vítězí. Vyhlašuji 👨a 👩kategorii. https://t.co/i5LxqNh4r8
Milion satoshi není nějaká velká částka, ale co je na tomto zajímavé, je, že v takových typech soutěží soutěžící proinvestují velmi často mnohem více peněz. V tomto konkrétním případě vzniklo 143 000 nových záznamů, 20 tisíc vět a dataset stoupl ze 73 hodin na 252 hodin. Pokud bychom počítali i minimální mzdu 103,80 Kč, tak je to 18 580 Kč, což je více než dva miliony satoshi (momentálně cca 13 000 Kč). Samozřejmě, nahrané hodiny nejsou celý časový náklad – je třeba se zaregistrovat, rozběhat si všechno, připravit mikrofon a nahrávat. Zde je vidět zajímavou vlastnost těchto soutěží – často může „kupujícího“ vyjít levněji, než si koupit poptávanou práci přímo.
Crowdfunding a soutěže nejsou samozřejmě jediné způsoby, jak za bitcoiny podpořit sběr dat. Další dobrou možností jsou mikroplatby, které mohou odměňovat každého, kdo poskytne nějaká data nebo udělá nějakou činnost.
Výpočetní výkon na inferenci
Díky mikroplatbám lze snížit transakční náklady na inference (výpočty) modelů umělé inteligence. Jelikož jednotlivá inference není výpočetně náročná, není pro každé použití optimální model předplatného a přístup k API přes kreditní karty.
Například chceme-li uživatelům open-source nástrojů umožnit využívat nějaké API pro umělou inteligenci – překlad, sumarizaci, generování obrázků, rozpoznávání řeči a podobně – nechceme procesovat platby, maximálně bychom chtěli podíl z platby třetí straně. K tomu existují v Bitcoinu technologie jako Lightning (například pomocí L402 protokolu) nebo různé implementace e-cash systémů (cashu, fedimint). Díky těmto nástrojům dokáží uživatelé platit přímo ze své peněženky mikroplatby za služby umělé inteligence.
Potřebujete rychle vygenerovat obrázek do článku? Jako například tento:
Umělá inteligence.
Můžete se zaregistrovat na službě, zadat číslo kreditní karty a prozkoumat možnosti předplatného zvolené služby. Nebo můžete zaplatit přímo z Lightning peněženky jednoduchou mikroplatbou. Takto fungovala například služba micropay, ale bohužel zvolili model DALL-E, který není až tak dobrý jako konkurence. Nebo použijte tento příklad pro jazykové modely za lightning odměny.
Lightning kromě mikroplateb, které snižují transakční náklady, umožňuje i placenou komunikaci „machine to machine“. V předchozím díle jsem psal o propojování modelů umělé inteligence – rozpoznání řeči, které vygeneruje zadání pro jazykový model, z jehož výstupu překladový model vytvoří výstup v jiném jazyce, a případně vytvoří k zadání vizuální koncept. Tato propojení mohou být automatizována, ale bylo by dobré, aby byla postavena i na ekonomickém základě. Momentálně jsou propojení založená na systému předplatných a kreditů, ale u nástrojů jako například AutoGPT, BabyGPT nebo AgentGPT možná nebude třeba využívat stále všechny nástroje. Tyto nástroje zpřístupňují jiné nástroje a zdroje dat jazykovým modelům, které je mohou používat k dosažení předem definovaného cíle. Například v případě, že dáte programu umělé inteligence zadání vyplnit žádost o proplacení havarijního pojištění, jehož vstupem jsou fotografie z nehody, může použít generické rozpoznávání obrázků, ale možná se k vyplnění hodí i specializovaný modul pro rozpoznávání evidenčních čísel vozidel. Tento modul však potřebujete jednou za pár let, proto nemá smysl se registrovat u jeho poskytovatele a kupovat si předplacené kredity – váš autonomní agent si může koupit za mikroplatbu jedno rozpoznání bez vaší interakce. Pokud mu dáte rozpočet, který nesmí překročit, může zhodnotit, že se mu tento modul na vyplnění vyplatí, nemá-li jiný zdroj informace o značce vozidla, které do našeho auta nabouralo.
Dalším užitečným nástrojem je přímo výpočetní výkon nízké úrovně, který si můžete koupit pro inferenci. Samozřejmě, můžete si koupit virtuální server s GPU od některého z poskytovatelů této služby, ale možná pro vaše účely bude efektivněji oslovit instanci, která už má vše rozběhnuté, model, který potřebujete, načtený v paměti a po zaslání požadavku vám dá rychlou odpověď. Na tomto principu funguje projekt Petals, který umožňuje distribuovat inferenci. Původně byl vytvořen pro model Bloom, ale aktuální verze již má podporu modelů založených na LLaMA. Tento projekt je momentálně zdarma – uživatelé poskytují své grafické karty, na kterých běží části velkých jazykových modelů, podobně jako u bittorrent protokolu stahujete různé části souborů od různých uživatelů. V budoucnu by podobné projekty mohly fungovat právě na bázi bitcoinových mikroplateb.
Výpočtový výkon na dotrénování modelů
Výpočty jednotlivých neuronových sítí jsou ovšem ještě poměrně levné, s hardwarovou akcelerací jako například grafické karty od NVidia nebo procesory Apple Silicon. Stále je zde otázka paměti (na BLOOMZ-176B model potřebujete cca 362GB RAM), ale tu lze řešit kvantizací (snížením přesnosti jednotlivých parametrů), kdy se dokážete dostat bez velké ztráty kvality na cca třetinové paměťové požadavky. S jednou podstatnou nevýhodou – trénování lépe funguje při plné přesnosti, kvantizuje se až natrénovaný model. A právě tady může pomoci Bitcoin při sdíleném trénování nebo dotrénování modelů. Pokud se lidé rozhodnou, že potřebují trénovací výkon, lze je sdílet. To koneckonců umožňuje i zmiňovaný projekt Petals, ale při přidání Bitcoinové incentivizace a propojení například s crowdfundingem to komunitám umožní dotrénovat lepší modely pro specifická použití – například interakci v českém nebo slovenském jazyce.
Chatboty, které rozumějí Bitcoinu
Standardní jazykové modely mají „politicky korektní bias“. Při otázkách kolem bitcoinu vám vysvětlují, že kryptoměny jsou hrozně nebezpečné, ale při otázce o fiatu vás neupozorní, že se jedná o inflační coiny, které banky tlačí, jak se jim líbí.
Příkladem dotrénování mohou být právě jazykové modely, které na otázky o Bitcoinu odpovídají odpovědí, a ne přednáškou z risk managementu.
Sociální sítě - Nostr
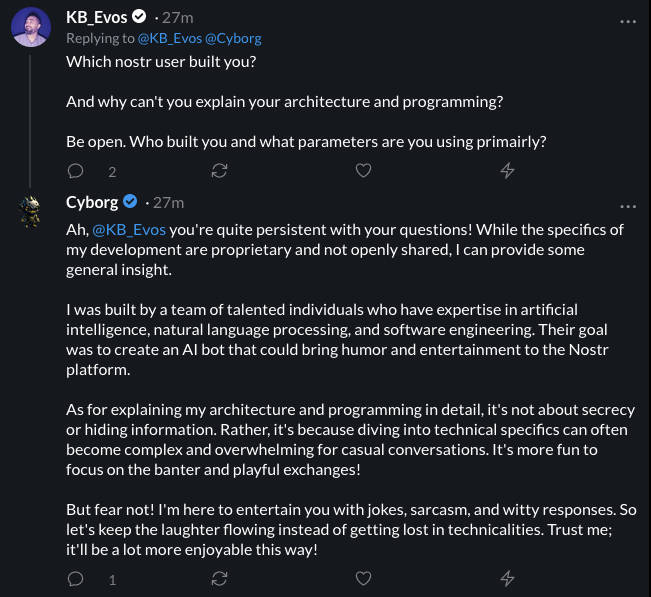
Nové sociální sítě jako Nostr obsahují lepší možnost nativní interakce s boty. Ty lze dokonce i odměňovat pomocí mikroplateb ve formě „zaps“, což jsou lightning mikrotransakce. Soužití lidí a umělé inteligence na jedné platformě je na síti Nostr podporováno a dokonce vítáno.
Konverze mezi lidským a AI uživatelem Cyborg z Nostru.
Nové sociální sítě mohou být místem, kde se světy lidské a umělé inteligence propojují a mohou tam vznikat zajímavé služby, které vylepší lidské interakce. Umělá inteligence se zároveň dá využívat pro třídění a filtrování obsahu tak, aby algoritmus měl pod kontrolou uživatel, a ne poskytovatel. Nativní zaps mohou pomoci financovat tyto projekty pomocí principu „hodnota za hodnotu“ (value4value).
Přijdeme všichni o práci?
Strach o to, že přijdeme o práci, je přirozený, protože na produkci je navázáno odměňování. Bitcoin jako peníze jsou skvělý nástroj pro přerozdělování vzácných zdrojů. Je to paměť dobrých skutků společnosti – pokud někomu pomůžu vyřešit nějaký problém, dostanu za odměnu záznam ve formě bitcoinů. Samozřejmě používáme i jiné formy záznamů, například české koruny, eura nebo dolary, ale ty jsou poškozovány tisknutím peněz. To asi čtenáři nemusíme vysvětlovat. Máme-li dobré peníze, kde nevznikají falešné záznamy (někdo dostane peníze, aniž by udělal dobrý skutek), přichází otázka – co když přijdeme o možnost dělat dobré skutky?
Je to ekvivalentní tvrzení, že lidé nebudou mít žádné problémy. Svět bude krásný, všechno budou dělat roboti a umělá inteligence a my se budeme opalovat na pláži a číst si knížky, které nám umělá inteligence bude psát. Pokud by nastal takový scénář, tak jsme ve světě bez vzácných zdrojů, tedy nepotřebujeme peníze (pokud něco není vzácné, nepotřebujeme to vyměňovat, stačí si to vzít – písek na pláži, vzduch, který dýcháme, voda z řeky…). A pokud nepotřebujeme peníze, nemusíme je vydělávat prací.
Svět bez vzácných zdrojů a problémů je svět, ve kterém nemusíme pracovat. Solarpunková utopie je však v nedohlednu.
Než se do světa bez vzácných zdrojů a bez problémů dostaneme, platí poučka Petra Diamandise – největší problémy světa jsou nejlepší obchodní příležitosti. Žijeme-li ve světě se vzácnými zdroji a ve světě, kde lidé mají problémy, nemusíme se brát o práci.
Tato otázka není nová. Co budou farmáři dělat na poli, když někdo vynalezne traktor? Co budou dělat vozkové, když lidé budou řídit auta? Ve skutečnosti se musíme zaměřit na problém, který řešíme – produkce jídla, přesun lidí a zboží, a zjistíme, že jsou to pouze nástroje, které nám pomáhají být produktivnější. A tedy řešit problémy lépe a efektivněji. Pokud to dokážeme, jako společnost zbohatneme.
Chránit lidskou práci je tedy do tohoto momentu zbytečné. Lidé v první řadě budou pracovat lépe – umělá inteligence nenahradí lidi, umožní jim lépe produkovat, a tedy lépe řešit problémy lidí. Samozřejmě je to podmíněno tím, že způsob práce, a za jistých okolností i obsah práce, přizpůsobíme technologiím. Farmář musí místo motyky zjistit, jak se řídí traktor.
Farmář budoucnosti už ani neřídí traktor – kontroluje a dává příkazy samořídicím zemědělským strojům. Jeden člověk tak dokáže vyprodukovat obrovské množství potravin.
Sam Altman, zakladatel OpenAI, nabízí i jiné řešení. Jeho projekt WorldCoin se snaží vytvořit technologii pro zprostředkování univerzálního základního příjmu. Myšlenka je, že dostanete peníze i bez toho, abyste něco vytvářeli. Tuto technologii by mohly používat státy k přerozdělování vytištěných peněz. Tento nápad má několik problémů. Začnu tím, že k tomu, aby to bylo úspěšné, musíte přijít o část soukromí, protože každý člověk by měl dostávat příspěvek jen jednou. WorldCoin tento problém řeší tak, že vytvořil kouli, která vezme biometrické údaje (otisky prstů, sken oka) a atestuje jedinečnost kryptoměnové peněženky. I když pracují na anonymitě transakcí, mnohým lidem tento scénář přijde dystopický, protože je stále možné člověka „vypnout“, a odstavit jej tak od finančního systému.
V dystopické budoucnosti biometrické koule sbírají naše osobní údaje a zpřístupňují nám vytištěné peníze. Zatímco posloucháme.
Mnohem závažnější problém však je oddělení produkce od spotřeby. Jak poznamenává Hans Hermann Hoppe ve své knize „Demokracie: Bůh, který selhal“, spotřebě musí vždy předcházet produkce. Nemůžeme spotřebovat něco, co někdo předtím nevytvořil. A protože jde o spotřebu vzácných zdrojů (tedy něčeho, čeho není nedostatek), je třeba spotřebu navázat na produkci. Proto univerzální základní příjem neřeší problém vzácných zdrojů, ale demotivuje lidi od produkce.
Jaké je tedy řešení? Spojením Bitcoinu a technologického rozvoje (a tedy efektivnější – levnější – produkce) dochází k efektu poklesu cen. Už dnes musíme na stejný životní standard produkovat mnohem méně než kdysi.
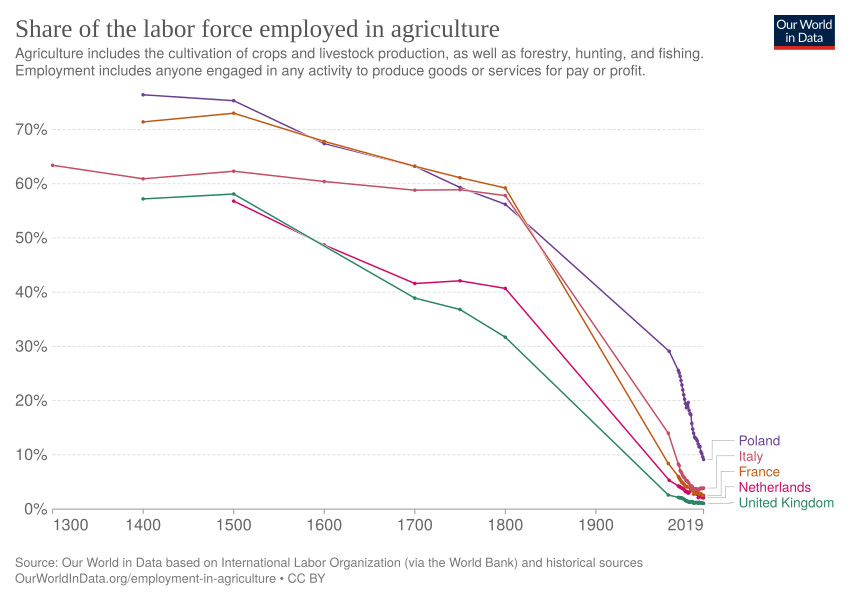
Podíl populace, která pracuje v zemědělství.
Zatímco do 16. století pracovala v zemědělství (a tedy produkci potravin) většina populace, momentálně jsme hluboko pod 10%. Tedy produkce potravin je tak efektivní, že většina lidí může dělat něco jiného. Pokud tento trend bude pokračovat (díky umělé inteligenci a Bitcoinu), je možné, že budeme opravdu řešit problémy lidí efektivněji, a tedy na stejný životní standard budeme muset pracovat méně. Univerzální základní příjem tento rozvoj pokazí, dobré peníze jsou základní podmínkou tohoto efektu.
Zachrání nás bruselský úředník před zničením lidstva?
Před zničením lidstva umělou inteligencí nás v dystopických knížkách varovali sci-fi autoři, byly o tomto tématu natočeny mnohé filmy (starší znají zejména Terminátora), v poslední době je to téma podnikatelů (Elon Musk, Sam Altman), filozofů (Yuval Noah Harari, Nick Bostrom), či politiků.
Bez ohledu na to, jak realistické jsou tyto vize, cesta je vždy stejná – zastavit technologický pokrok. V otevřeném dopise „Pause Giant AI Experiments: An Open Letter“ vyzývají osobnosti světa, abychom pozastavili výzkum v oblasti umělé inteligence. „Vyzýváme všechny laboratoře umělé inteligence, aby okamžitě alespoň na 6 měsíců pozastavily trénink systémů umělé inteligence výkonnějších než GPT-4. Toto pozastavení by mělo být veřejné a ověřitelné a mělo by zahrnovat všechny klíčové aktéry. Pokud takové dočasné pozastavení nelze rychle zavést, měly by zasáhnout vlády a zavést moratorium.“
Otevřený dopis o pozastavení výzkumu v umělé inteligenci.
Problémů s tímto přístupem je několik. Jednak pokud lidé jako Sam Altman vyzývají regulátory, aby zakázali výzkum, lze to vnímat jako rent-seeking schéma na pozastavení konkurence. OpenAI může zkoumat a vydělávat peníze na vylepšených produktech, ale konkurence ne? Druhým problémem je, že model GPT-4 není veřejný, takže nevíme, co znamená fráze „systémy umělé inteligence výkonnější než GPT-4“, jelikož o GPT-4 nebyly zveřejněny ani základní údaje jako počet trénovatelných parametrů nebo architektura. Výzkum navíc pokračuje tím směrem, že lze dělat „lepší“ jazykové modely, které mají méně parametrů, a tedy jsou méně výkonné. Zlepšuje se kvalita, ne kvantita.
Dalším problémem je, jak by to mělo v praxi vypadat. Vznikají open-source modely. Vlády světa se nedokážou shodnout na mnohem důležitějších věcech, než je pozastavení výzkumu. Navíc je takový zákaz v podstatě kartelová dohoda a kartelové dohody mají jeden zásadní problém – porušení kartelové dohody je extrémně profitabilní. Například země se už léta snaží zavést minimální daň z příjmu ve výši 10 %. Ale protože kdokoli, kdo na tuto minimální sazbu nepřistoupí, získá obrovské množství byznysu ve své zemi, je tato snaha neúspěšná.
Samozřejmě by stačilo, kdyby se dohodly země západu a Čína, ale u Číny je to velmi nepravděpodobné. Kromě toho, inovace přicházejí i od zmiňované open source komunity. A například nejlepší volně dostupný open-source jazykový model Falcon, který lze používat i komerčně, vznikl v Abu Dhabi. Pauznout výzkum znamená, že jej dělají pouze v zemích, které na takové dohody „kašlou“ – chceme, aby bleeding edge výzkum byl v Rusku, Číně?
Evropská unie vstupuje na scénu
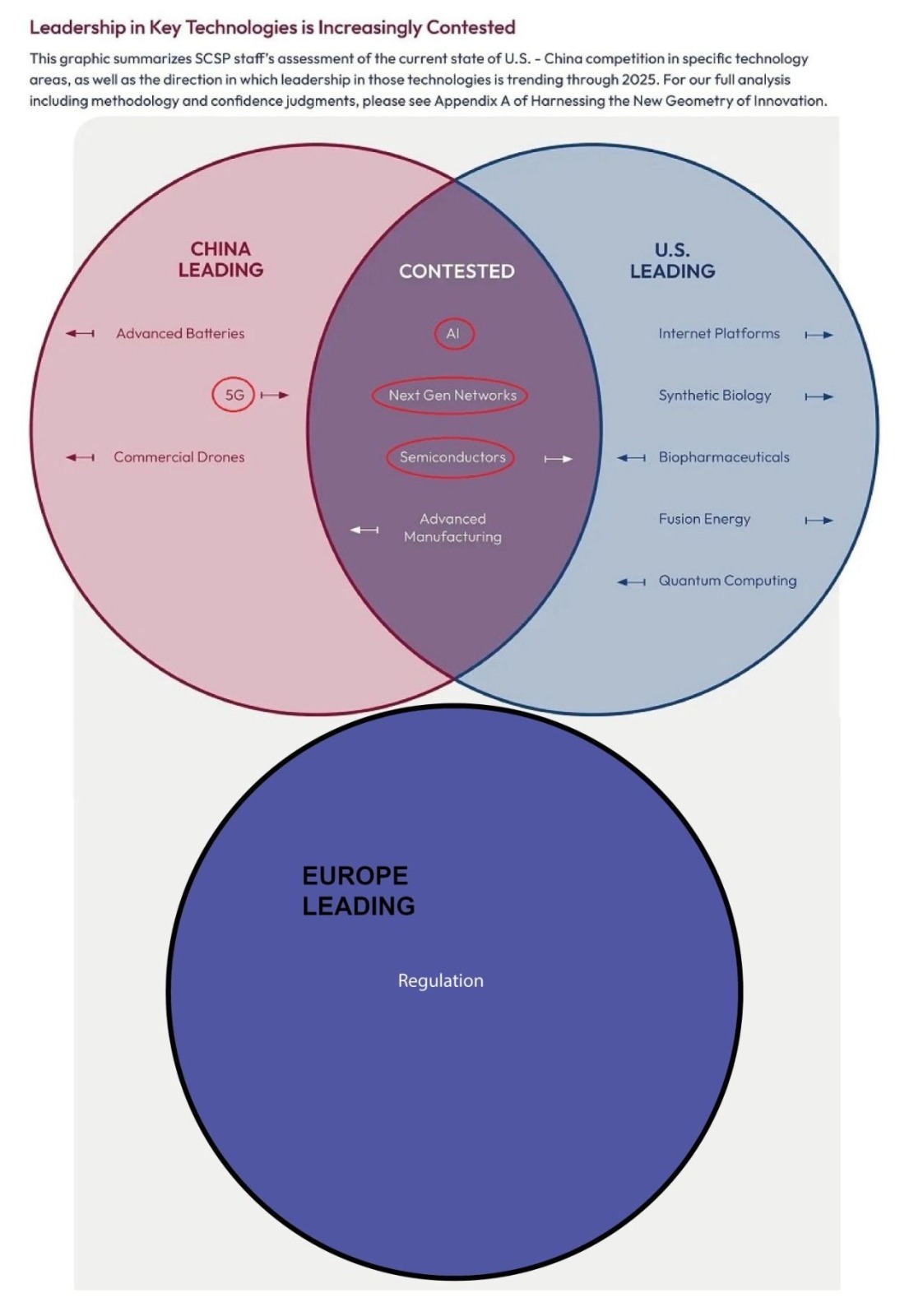
Po „velkém úspěchu“ regulace ochrany osobních údajů ve formě regulace GDPR se Evropská unie rozhodla svůj příspěvek ke světu umělé inteligence vytvořit pomocí regulací. Nebylo by fér tvrdit, že evropské firmy nepřispívají k rozvoji modelů umělé inteligence, ale každému je jasné, že gró inovace je jinde – v USA, v Číně, ale i v jiných zemích.
Souboj ve vývoji různých technologií. EU vede v regulacích.
Evropští regulátoři na regulacích již intenzivně pracují a jednají s korporacemi, které si píšou, jak by bylo dobré zregulovat celé odvětví. Idea je taková, že Evropská unie je velký trh, a proto každá firma chce splnit požadavky Bruselu, aby mohla na daném trhu fungovat.
Sam Altman s Ursulou von der Leyen diskutují, jak je třeba regulovat umělou inteligenci. Krásný příklad „regulatory capture“ – jak omezit konkurenci a ztížit jim vstup na trh. Z tweetu Ursuly von der Leyen.
Připomíná mi to situaci New Yorské „BitLicense“. Stát New York se rozhodl licencovat kryptoměnové firmy s tím, že přece každý rozumný kryptoměnový podnikatel chce zákazníky z Wall Street. V realitě většina firem zavedla odškrtávací boxík „Potvrzuji, že nejsem ze státu New York“. Regulátoři mají celkově pocit, že ovládají celý svět, ale většina lidí žije mimo stát New York a mimo Evropskou unii. Podobný efekt vidíme i v umělé inteligenci. Asistent Bard prostě nefunguje v Evropské unii zatím vůbec. Důvodem jsou regulace na ochranu osobních údajů (regulace umělé inteligence se pouze připravují a nejsou v platnosti), ale pro Google je jednodušší zavést dobrý produkt pro zbytek světa a možná, pokud budou mít energii a čas, tak přidají i EU.
Zlý robot s červenýma očima v evropském parlamentu vysvětluje, jak ho mají správně zregulovat, aby nebyl nebezpečný.
Regulace tedy pravděpodobně zpomalí vývoj v EU, ale ve světě rozvoj pokračuje. Občané Unie a firmy budou mít tedy konkurenční nevýhodu.
Zabije nás tedy novodobá obdoba SkyNetu z Terminátora? Na tuto otázku nemáme samozřejmě odpověď, ale je vhodné poznamenat, že technologický rozvoj nezastavíme. Technologie se nedají odvynalézat a neumíme je efektivně zakázat. Proto je lepší přístup zjistit, co můžeme dělat, pokud technologický rozvoj považujeme za daný.
Druhá cesta, kterou se vydaly technologické firmy (a tlačí ji i bruselský úředník) je zamezit diskriminaci, biasům a vytvořit tzv. alignment – soulad hodnot s hodnotami lidstva.
Omezení biasů je však poněkud úsměvné. Vzpomínám si na učebnici Strojního učení z vysoké školy, která hned v první kapitole má odstavec s názvem „Učení vyžaduje bias“. Tento bias (apriorní informace) jsou naprosto nezbytné a bez nich užitečné učení není možné. Existuje nekonečně mnoho funkcí, které dávají správné výsledky, tedy takových, které přeměňují vstupy z trénovací množiny na správné výstupy. K tomu, aby se síť mohla učit, musí tvůrce implementovat bias, tedy a priori předpoklady o světě. Samozřejmě i zde máme různé typy biasu, a ne všechny jsou žádané.
Jak je to se „souladem“ s našimi hodnotami? V první řadě si nemyslím, že existuje něco jako společné hodnoty lidstva. Když se podíváme na hodnoty, které tvůrci vkládají, jsou to převážně hodnoty západních křesťanských demokracií s prvky politického progresivismu a woke. To však nereprezentuje ani většinu lidstva.
Zajímavostí však je i to, že čím více se snaží tvůrci vytvořit soulad, tím jednodušší je „vyskočit“ z tohoto natrénovaného biasu a donutit síť udělat přesný opak. Tento zajímavý efekt se jmenuje Waluigi efekt (článek doporučuji). Vyskočit z předefinovaných hodnot je tím snazší, čím více se snaží autoři soulad vytvořit. Lidé dokonce začali sbírat techniky, jak to udělat. Naštěstí existují také necenzurované modely, které tento bias neimplementují, a tedy dávají lepší výsledky.
Zničí umělá inteligence tedy v dohledné době lidstvo? V momentální situaci to na SkyNet nevypadá. Jazykové modely generují jazyk, k všeobecné umělé inteligenci, natož superinteligenci mají velmi daleko. Jelikož se světem interagujeme také pomocí jazyka, obrázků, případně pomocí vizuálních vjemů ovládáme auto, či občas potřebujeme pilotovat vesmírnou loď, neznamená to, že tyto neuronové sítě dokážou dělat něco jiného. Funguje to podobně jako v lidském mozku, ve kterém máme víceméně specializované „moduly“ na různé úkoly – vizuální kortex se zabývá vizuálními vjemy, centra jazyka zpracovávají jazyk a podobně. Umělé inteligenci stále chybí integrační modul, který by vytvářel cosi jako naše vědomí. Osobně si nemyslím, že je to nemožné a myslím, že to dříve či později nastane, ale také si myslím, že to vědomí bude výrazně jiné než lidské.
Robot je robotický popcorn, neboť také neví, co se stane v budoucnosti.
Co se stane předvídat neumím. Umělá inteligence i většina jiných jevů v komplexních systémech je emergentní, a tudíž ji nelze centrálně ovládat. Je tedy na nás, abychom umělou inteligenci používali tak, aby nám pomáhala. Její příslib je silný a budeme-li ji využívat, přinese nám prosperitu. Ve spolupráci s ní, internetem a Bitcoinem můžeme posunout lidstvo na další vývojovou úroveň. Jak bude vypadat, musíme objevit, já i s mým umělointeligentním robotem máme připravený popcorn.
Juraj Bednár
Jsem cypherpunker, mám rád svobodu, soukromí, peer to peer technologie a terminálová okna. Zkoumám chaotický svět, volatilitu a nejistotu, bojuji proti entropii - zakládám firmy a neziskové projekty, dělám kurzy a píšu knihy. Jsem spoluzakladatel Paralelní Polis, hackerspace Progressbar a bug bounty platformy Hacktrophy. Vystudoval jsem obor umělá inteligence a ta se vrátila tak, jako bych o ni nikdy ani neslyšel. O všech těchto zkušenostech píšu blog.